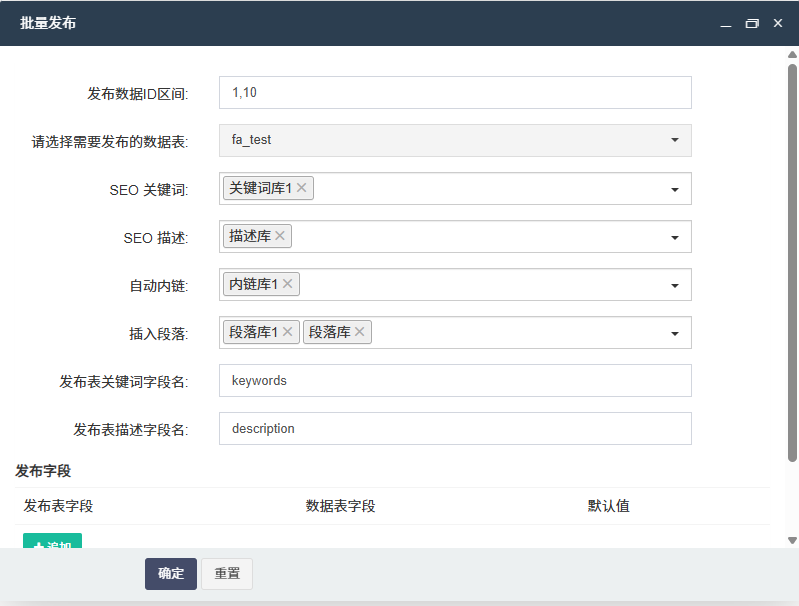
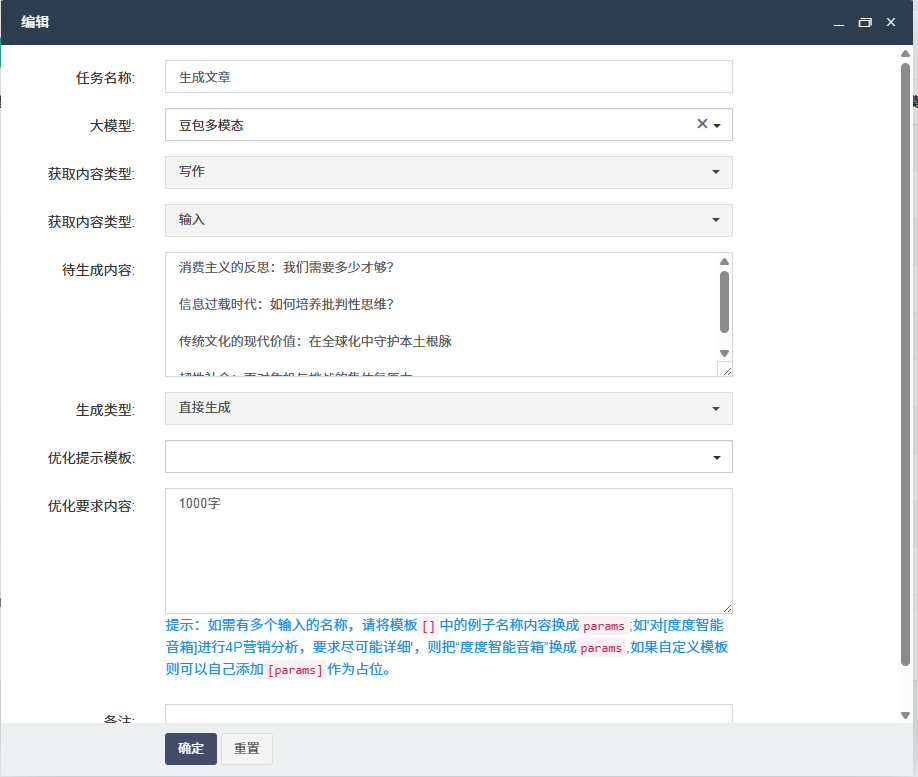
在使用 FastAdmin 进行文章自动生成时,常常会遇到生成文章语义不通的问题,这极大地影响了内容质量和使用体验。不过,通过一些 AI 模型优化技巧,我们可以有效改善这一状况。
首先,要对训练数据进行优化。AI 模型的训练数据质量直接影响其生成内容的质量。对于 FastAdmin 自动生成文章的场景,我们需要收集大量语义连贯、逻辑清晰的相关文本数据。这些数据可以来自权威的新闻网站、专业的行业报告等。在收集到数据后,还需要对其进行清洗和预处理。去除数据中的噪声、错误信息以及不规范的表达,统一文本格式。例如,将所有的文本转换为小写,去除多余的空格和标点符号等。通过这样的操作,可以让 AI 模型学习到更优质的数据,从而提高生成文章的语义连贯性。
其次,调整模型的超参数也是关键的优化技巧。不同的超参数设置会对模型的性能产生不同的影响。在 FastAdmin 结合的 AI 模型中,我们可以尝试调整学习率、批量大小和训练轮数等超参数。学习率决定了模型在训练过程中参数更新的步长,如果学习率过大,模型可能会跳过最优解;如果学习率过小,模型的训练速度会非常缓慢。批量大小则影响模型的训练效率和泛化能力,合适的批量大小可以让模型在训练过程中更好地收敛。训练轮数决定了模型对训练数据的学习次数,过多的训练轮数可能会导致模型过拟合,而过少的训练轮数则可能使模型学习不充分。通过不断地试验和调整这些超参数,找到最适合的组合,能够提升模型生成文章的质量。
再者,采用集成学习的方法也能有效应对语义不通的问题。集成学习是将多个不同的模型组合起来,通过综合它们的预测结果来提高整体性能。在 FastAdmin 自动生成文章的场景中,我们可以选择多个不同架构的 AI 模型,如基于循环神经网络(RNN)和基于Transformer架构的模型。让这些模型分别对同一输入进行处理,然后将它们的输出结果进行融合。可以采用简单的投票法,即选择出现次数最多的结果作为最终输出;也可以采用加权平均法,根据每个模型的性能为其分配不同的权重,然后计算加权平均值作为最终结果。通过集成学习,可以充分发挥不同模型的优势,提高生成文章的语义连贯性和逻辑性。
另外,对生成的文章进行后处理也是必不可少的环节。即使经过前面的优化,生成的文章仍然可能存在一些小的语义问题。我们可以使用一些自然语言处理技术对生成的文章进行检查和修正。例如,使用语法检查工具检查文章中的语法错误,使用语义相似度计算工具检查句子之间的逻辑关系。对于发现的问题,可以手动进行修改,也可以编写规则让程序自动进行修正。
总之,应对 FastAdmin 自动生成文章语义不通的问题,需要从训练数据优化、超参数调整、集成学习和后处理等多个方面入手,运用合适的 AI 模型优化技巧,不断提高生成文章的质量。


后台体验地址:https://demo.gzybo.net/demo.php
移动端体验地址:https://demo.gzybo.net/wx
账号:demo
密码:123456
联系我们




发表评论 取消回复