在AI应用日益普及的今天,将本地部署的Ollama模型集成到FastAdmin系统中,成为提升后台智能化管理效率的重要方式。通过自定义模型接入,开发者可以实现自然语言处理、智能问答等功能,而无需依赖第三方云服务。本文将详细介绍如何在FastAdmin中完成Ollama模型的本地部署与配置,帮助您快速搭建高效、安全的智能管理系统。
首先,确保您的服务器环境已安装并运行Ollama。Ollama是一款支持多种大语言模型(LLM)本地运行的开源工具,能够在Linux、macOS和Windows系统上部署。安装完成后,可通过命令行拉取所需模型,例如执行 ollama pull llama3 下载Meta发布的Llama3模型。启动服务后,默认监听在 http://localhost:11434,这是后续与FastAdmin通信的关键接口。此时,Ollama已具备接收HTTP请求并返回推理结果的能力。
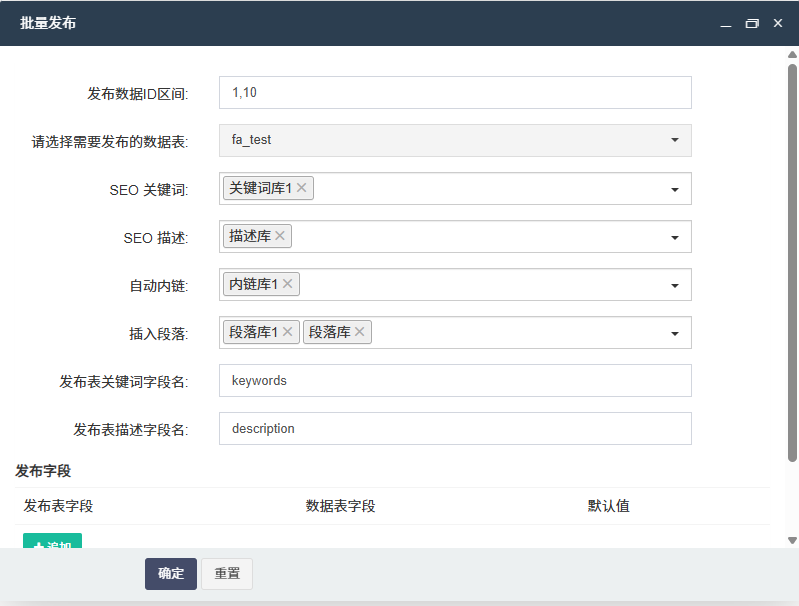
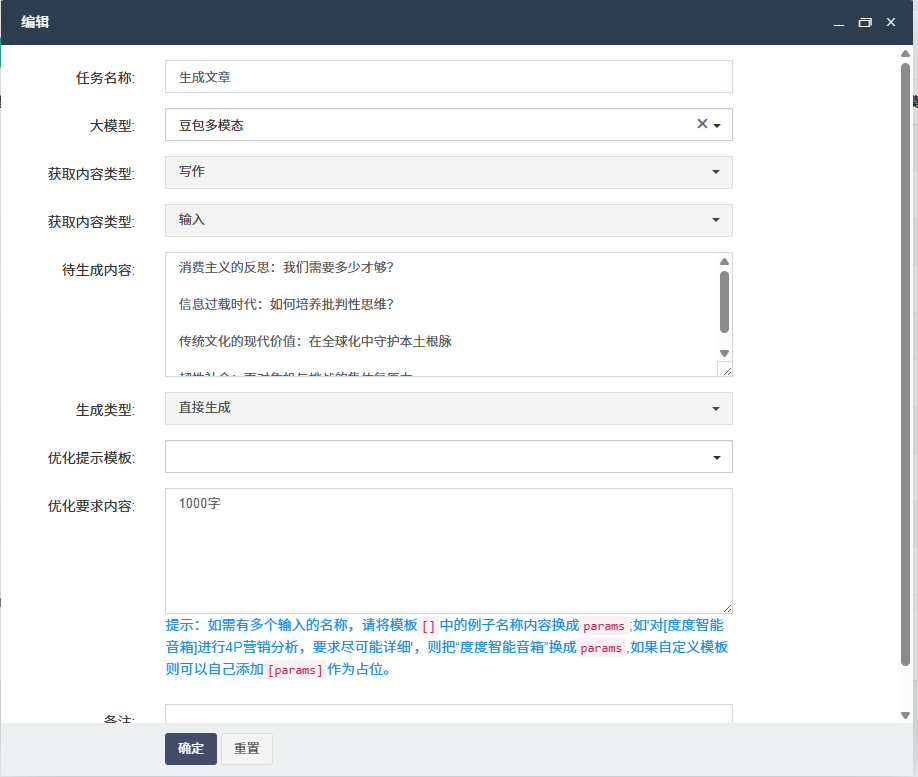
接下来,在FastAdmin项目中配置API调用逻辑。FastAdmin基于ThinkPHP框架开发,具备良好的扩展性。您可以在应用目录下创建一个名为 OllamaService 的类,用于封装与Ollama模型的交互。该类中需使用CURL或Guzzle等HTTP客户端发送POST请求至 http://localhost:11434/api/generate 接口,传递用户输入的提示词(prompt),并解析返回的JSON数据。注意设置超时时间和错误重试机制,以提升系统的稳定性。
为了实现自定义模型接入的安全性和可维护性,建议在FastAdmin后台添加配置页面,允许管理员动态设置Ollama服务地址、默认模型名称及请求参数(如temperature、max_tokens)。这些配置可存储在数据库或配置文件中,便于后期调整。同时,可在中间件中加入权限校验,确保只有授权用户才能触发模型调用,防止资源滥用。
在实际业务场景中,您可以将Ollama模型应用于内容生成、工单自动回复、日志分析等模块。例如,在客服管理系统中,当用户提交问题时,系统自动调用本地Ollama模型生成初步回复建议,供客服人员参考。这种方式既提升了响应速度,又降低了人力成本。由于模型运行在本地,所有数据无需上传至外部服务器,极大增强了数据隐私保护能力。
值得注意的是,在高并发环境下,Ollama可能因资源占用过高导致响应延迟。因此,建议结合队列任务(如使用Redis + Workerman)异步处理模型请求,并设置请求频率限制。此外,定期监控GPU/CPU使用率,合理分配计算资源,是保障系统稳定运行的关键。
最后,完成自定义模型接入后,务必进行充分测试。可通过FastAdmin的日志模块记录每次模型调用的输入输出,便于调试和优化提示词工程。同时,建立模型性能评估机制,对比不同模型在特定任务上的准确率与响应时间,持续迭代升级。
综上所述,通过在FastAdmin中配置本地部署的Ollama模型,不仅可以实现智能化功能拓展,还能确保数据安全与系统可控性。掌握这一自定义模型接入方法,将为您的企业级应用带来更强的技术竞争力。未来,随着更多轻量化模型的推出,本地AI集成将变得更加高效便捷。


后台体验地址:https://demo.gzybo.net/demo.php
移动端体验地址:https://demo.gzybo.net/wx
账号:demo
密码:123456
联系我们




发表评论 取消回复