12月7日消息,北京时间7日凌晨,Google公司突然放出了自己“迄今为止最强大、最通用的模型”Gemini。

Gemini是一款多模态模型,可以归纳并流畅地理解、操作以及组合不同类型的信息,包括文本、代码、音频、图像和视频。第一个版本 Gemini 1.0 推出3款不同尺寸模型:Ultra、Pro 和 Nano。

Gemini能理解“文本、代码、音频、图像和视频”五种信息
其中,Gemini Ultra是规模最大且功能最强大的模型,适用于高度复杂的任务;Gemini Pro是适用于各种任务的最佳模型;Gemini Nano是端侧设备上最高效的模型。
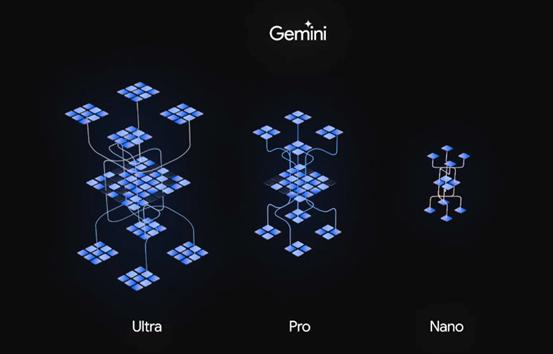
三种尺寸
目前,Gemini 1.0 现已在多种Google产品和平台上推出,包括接入聊天机器人Bard和智能手机Pixel 8 Pro 上。未来几个月,Gemini 将应用于Google更多的产品和服务,如Search、Ads、Chrome 和 Duet AI。
从12月13日开始,开发者和企业客户可以通过 Google AI Studio 或 Google Cloud Vertex AI 中的 Gemini API 获取 Gemini Pro。

谷歌CEO桑达尔•皮查伊(Sundar Pichai)表示:“我们正与 Gemini 一起迈入下一段旅程。Gemini 是我们迄今为止最强大、最通用的模型,它在许多领先的基准测试中都展现出了最先进的性能。”
Gemini Ultra性能超越GPT4
DeepMind CEO戴密斯•哈萨比斯(Demis Hassabis)对Gemini进行了详细介绍。

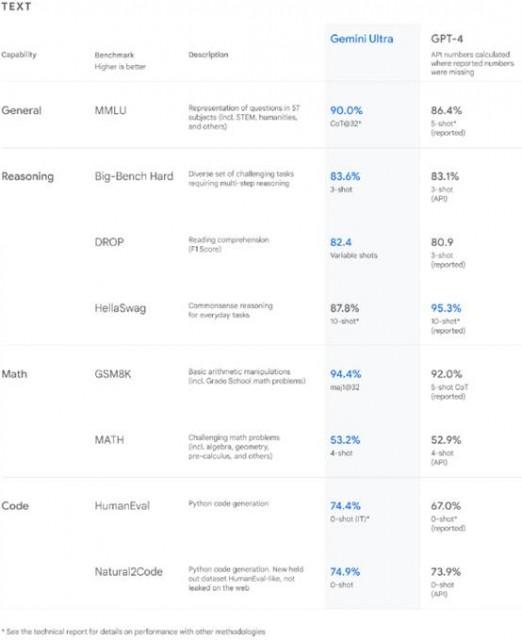
据介绍,从自然图像、音频和视频理解到数学推理,在被大型语言模型(LLM)研究和开发中广泛使用的 32 项学术基准中,Gemini Ultra 的性能有 30 项都超过了目前最先进的水平。
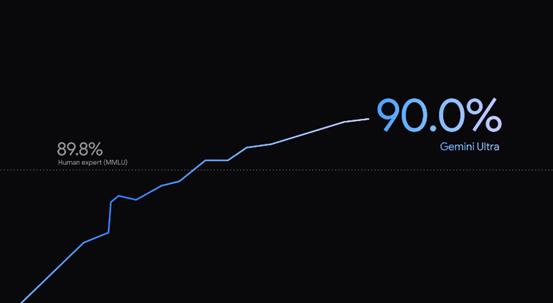
在 MMLU(大规模多任务语言理解)测试中Gemini Ultra 的得分率为 90.0%,是第一个超过人类专家的模型,GPT-4的得分率为86.4%。
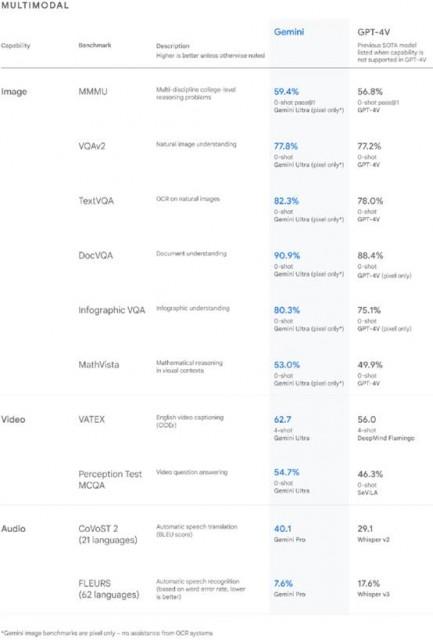
图像理解方面,在新的 MMMU 基准测试中,Gemini Ultra的表现也更优,其得分率达59.4%,GPT-4V的得分率为56.8%。
Gemini Ultra目前正在完成大规模的信任和安全检查,在模型的完善过程中Google将向部分客户、开发者、合作伙伴以及安全和责任专家提供 Gemini Ultra,以供其进行早期试验和提供反馈。并将在明年初向开发者和企业客户提供该模型。
最强AI模型Gemini性能展示
Gemini 1.0具有复杂推理能力,通过阅读、过滤以及理解信息,从数十万份文件中提取见解。
Google工程师演示了一个Gemini提取“20万份科学研究文献”关键信息的例子。
自2021年以来,该研究领域新增了20多万份研究论文,需要更新到原有(截止于202年)的研究中。
以往,科学研究人员只能手动来处理,现在Gemini能够自动区分和过滤与研究领域相关的文献信息,只需要一顿午饭的时间,Gemini帮科学家读完20万篇论文,并画出了更新数据信息后的新图片。
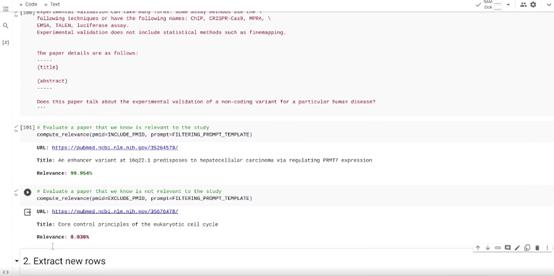
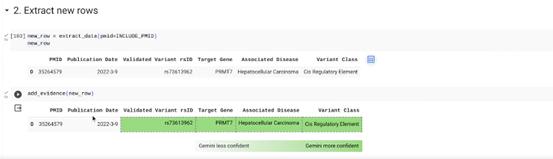
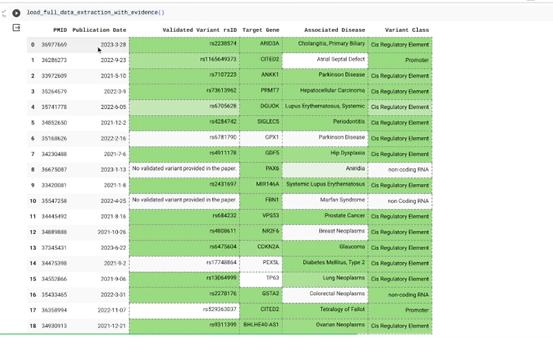
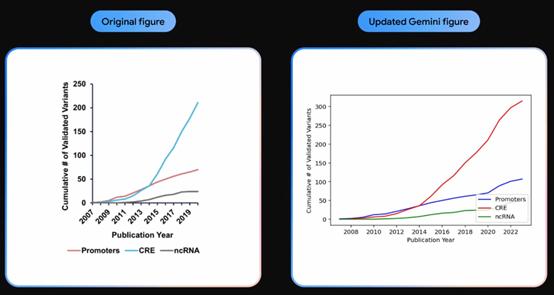
Google表示,Gemini 1.0这种从海量的数据中发掘难以辨别的知识内容的能力将有助于在从科学到金融等多个领域以数字化速度实现新的突破。
Gemini 1.0可以同时识别并理解文本、图像、音频等,因此它能更好地理解具有细微差别的信息,回答与复杂主题相关的问题。Gemini 1.0擅长解释数学和物理等复杂科目中的推理。
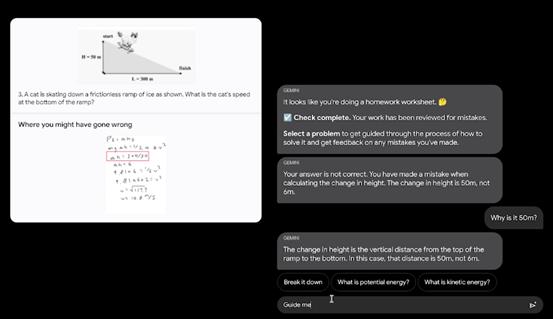
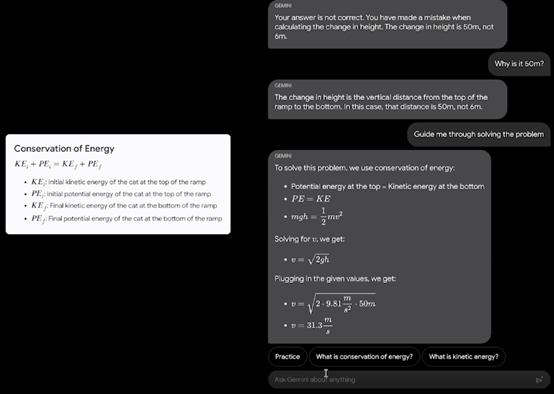
Google演示的例子展示了Gemini 1.0解复杂数学题的能力,和归纳整理同类题型的能力。
另外,Gemini 1.0 还可以理解、解释和生成Python、Java、C++、Go编程语言的高质量代码。

Google在两年前发布了编码工具AlphaCode,它是第一个在编程竞赛中性能达到竞赛水平的 AI 代码生成系统。
现在,利用Gemini,Google团队创建了更先进的代码生成系统 AlphaCode 2,它解决的问题的数量是AlphaCode 的2倍,编程能力超过85%的人类程序员。
另外,Google还发布了迄今为止功能最强大、效率最高且可扩展性最强的 TPU 系统 Cloud TPU v5p,旨在为训练前沿 AI 模型提供支持。新一代 TPU 将加速 Gemini 的开发,帮助开发者和企业客户更快地训练大规模生成式 AI 模型,从而更快推出新产品和新功能。



发表评论 取消回复